 Jeju Deep Learning Summer School, July 2018
Jeju Deep Learning Summer School, July 2018
Automated Curriculum Learning for Reinforcement Learning
How would you make an agent capable of solving the complex hierarchical tasks?
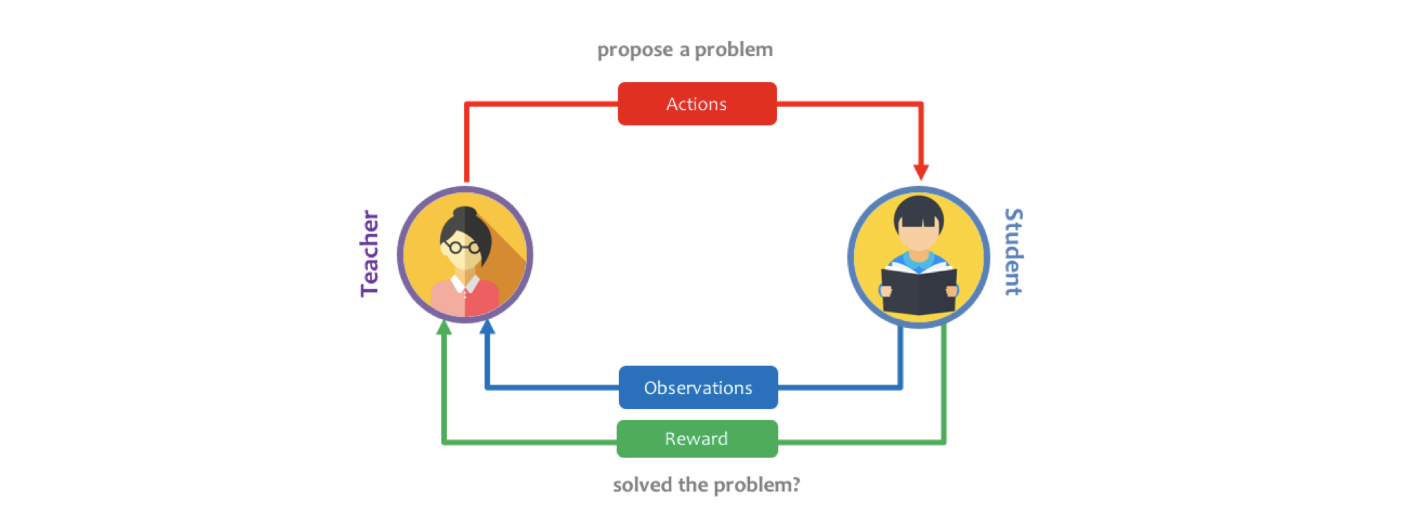
Imagine a problem that is complex and requires a collection of skills, which are extremely hard to learn in one go with sparse rewards (e.g. solving complex object manipulation in robotics). Hence, one might need to learn to generate a curriculum of simpler tasks, so that overall a student network can learn to perform a complex task efficiently. Designing this curriculum by hand is inefficient. In this project, I set out to train an automatic curriculum generator using a Teacher network which keeps track of the progress of the student network, and proposes new tasks as a function of how well the student is learning. I adapted an state-of-the-art distributed reinforcement learning algorithm, for training the student network, while using an adversarial multi-armed bandit algorithm, for teacher network. I also developed an environment, Craft Env, with possibility of hierarchical task design with a range of complexity that is fast to iterate through. I analysed how using different metrics for quantifying student progress affect the curriculum that the teacher learns to propose and demonstrate that this approach can accelerate learning and interpretability of how the agent is learning to perform complex tasks. In order to start, I adapted the Craft Environment from work by Andreas et al.,[1] as it has a nice simple structure with possibility of hierarchical task design with a range of complexity that is fast to iterate through. I have developed a fixed curriculum of simpler target sub-tasks (in craft environment: “get wood” “get grass” “get iron” “make cloth” “get gold”), and in the future will make a teacher network who proposes tasks for the student to learn. I could also kick-start the student with demonstrations from an expert.
I have interfaced IMPALA[2], a GPU utilised version of A3C architecture which uses multiple distributed actors with V-Trace off-policy correction, with my Craft Environment to train on all the possible Craft tasks concurrently. This is possible by providing the hash of the task name as instruction to the network (similar setup to DMLab IMPALA, using an LSTM to process the instruction).
I have interfaced IMPALA[2], a GPU utilised version of A3C architecture which uses multiple distributed actors with V-Trace off-policy correction, with my Craft Environment to train on all the possible Craft tasks concurrently. This is possible by providing the hash of the task name as instruction to the network (similar setup to DMLab IMPALA, using an LSTM to process the instruction).
Other papers that I am inspired by in this work include [3], [4].
References
[1] Modular Multitask Reinforcement Learning with Policy Sketches (Andreas et al., 2016)
[2] Automated Curriculum Learning for Neural Networks (Graves et al., 2017)
[3] Learning by Playing-Solving Sparse Reward Tasks from Scratch (Reidmiller et al., 2018)
[4] POWERPLAY: Training an Increasingly General Problem Solver by Continually Searching for the Simplest Still Unsolvable Problem (Schmidhuber, 2011)