Selected Publications
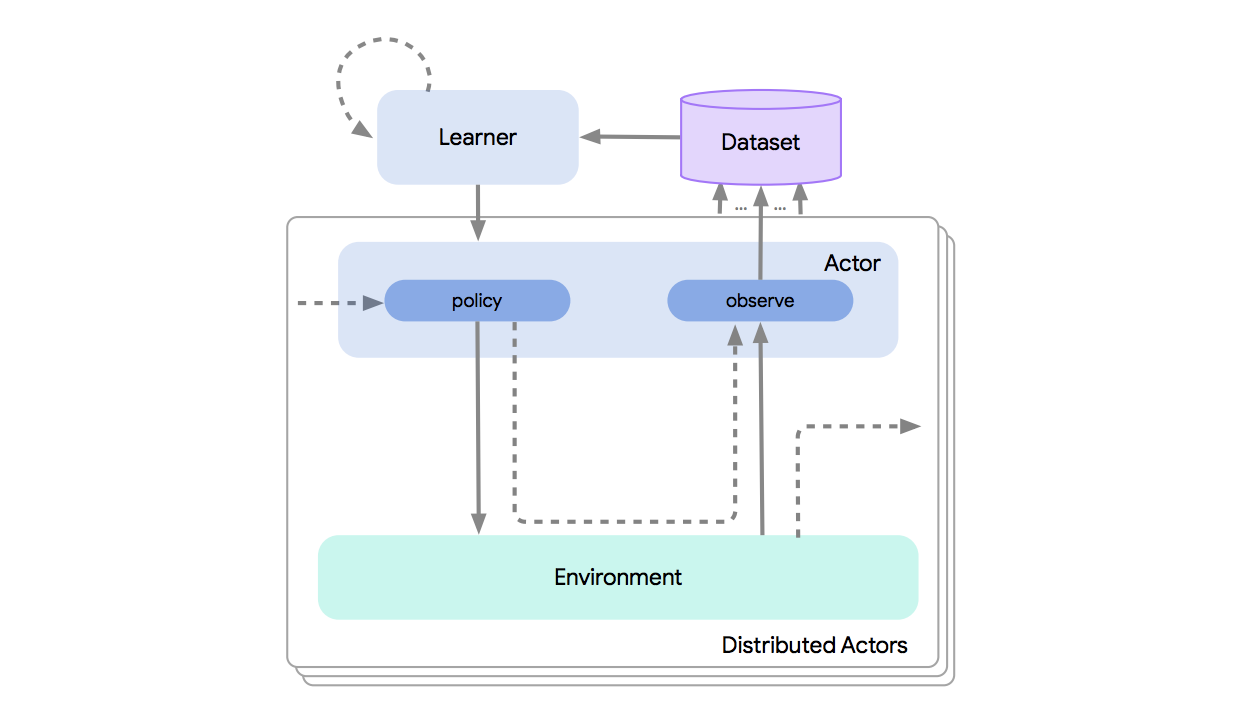
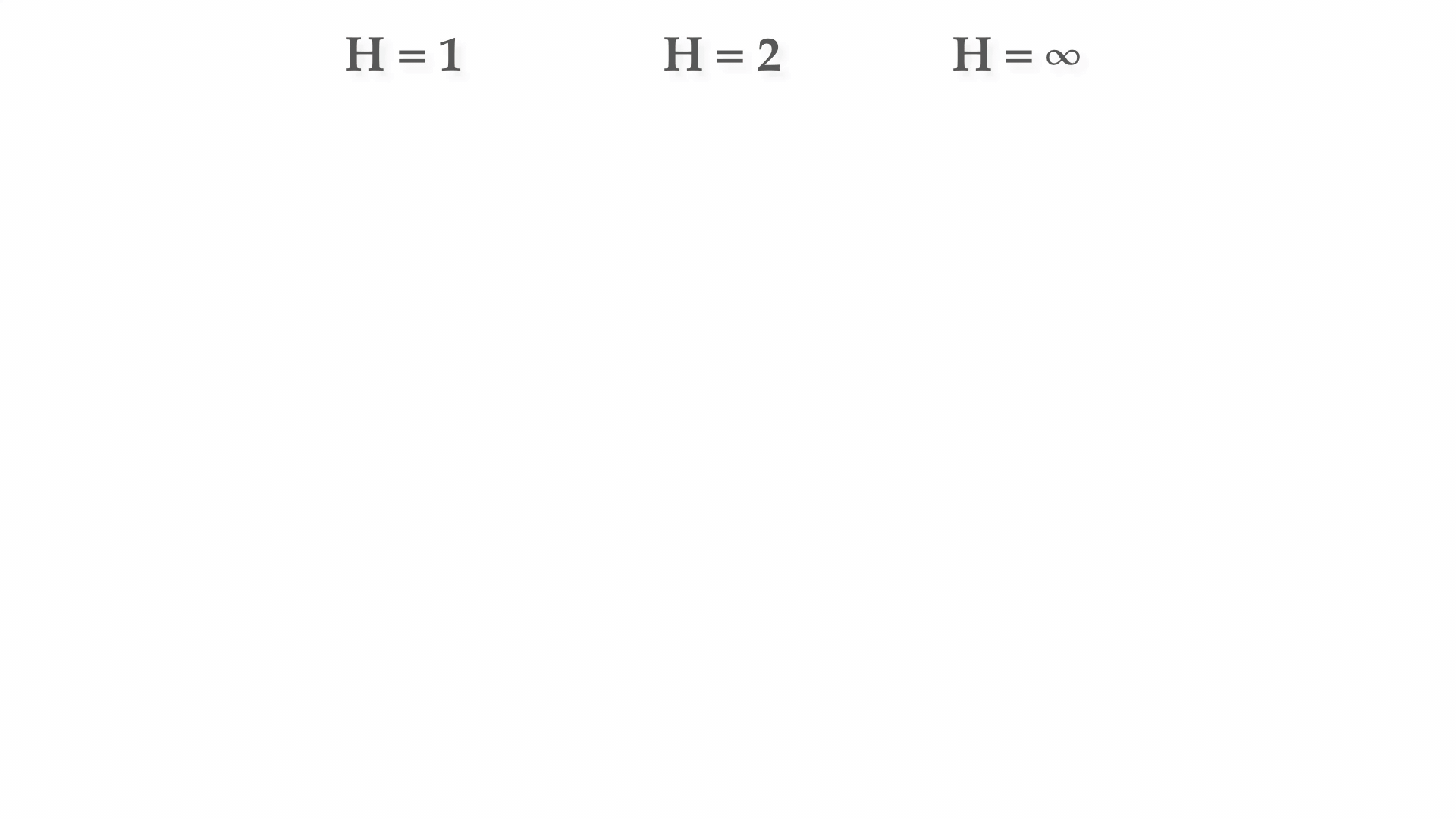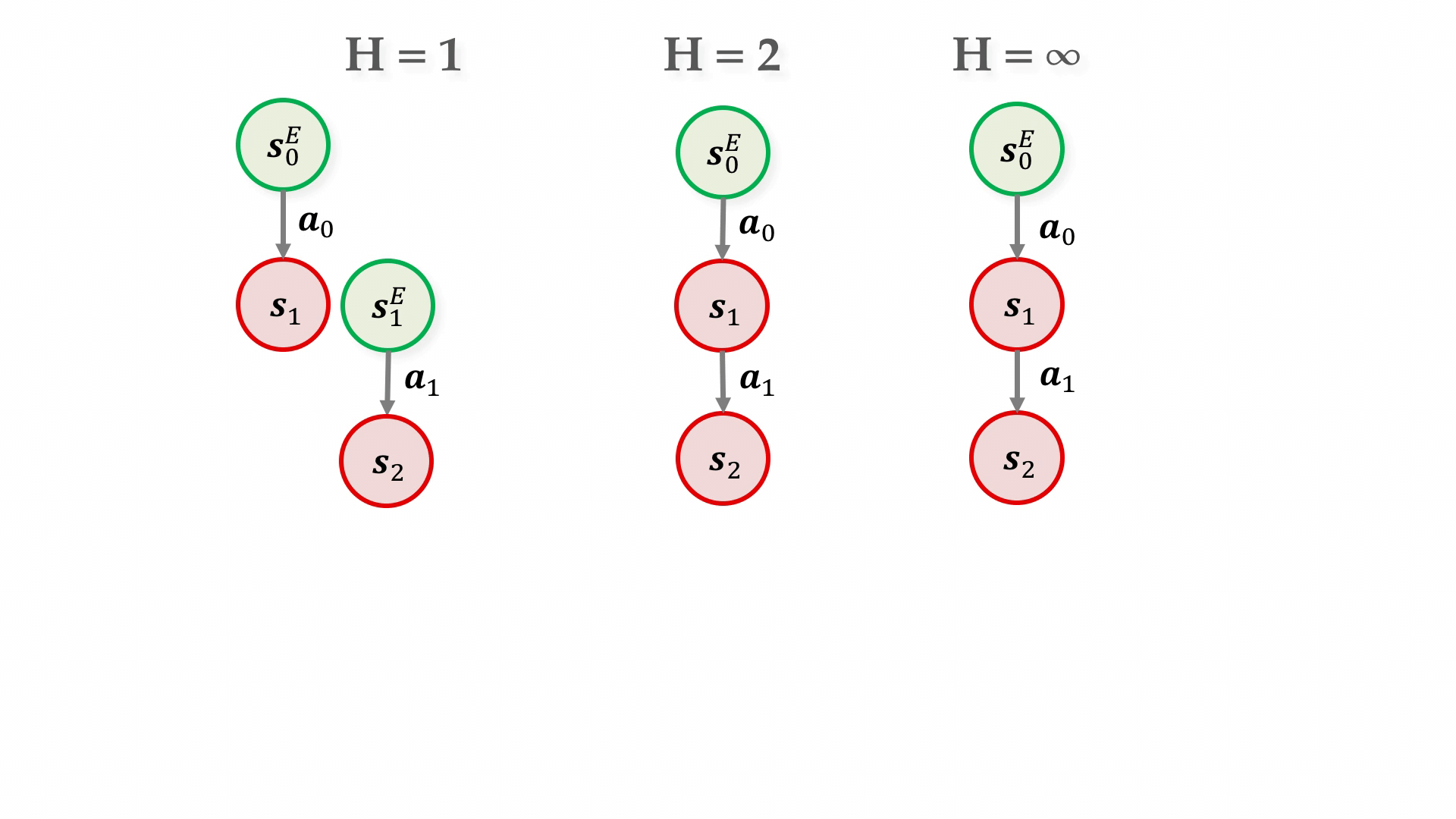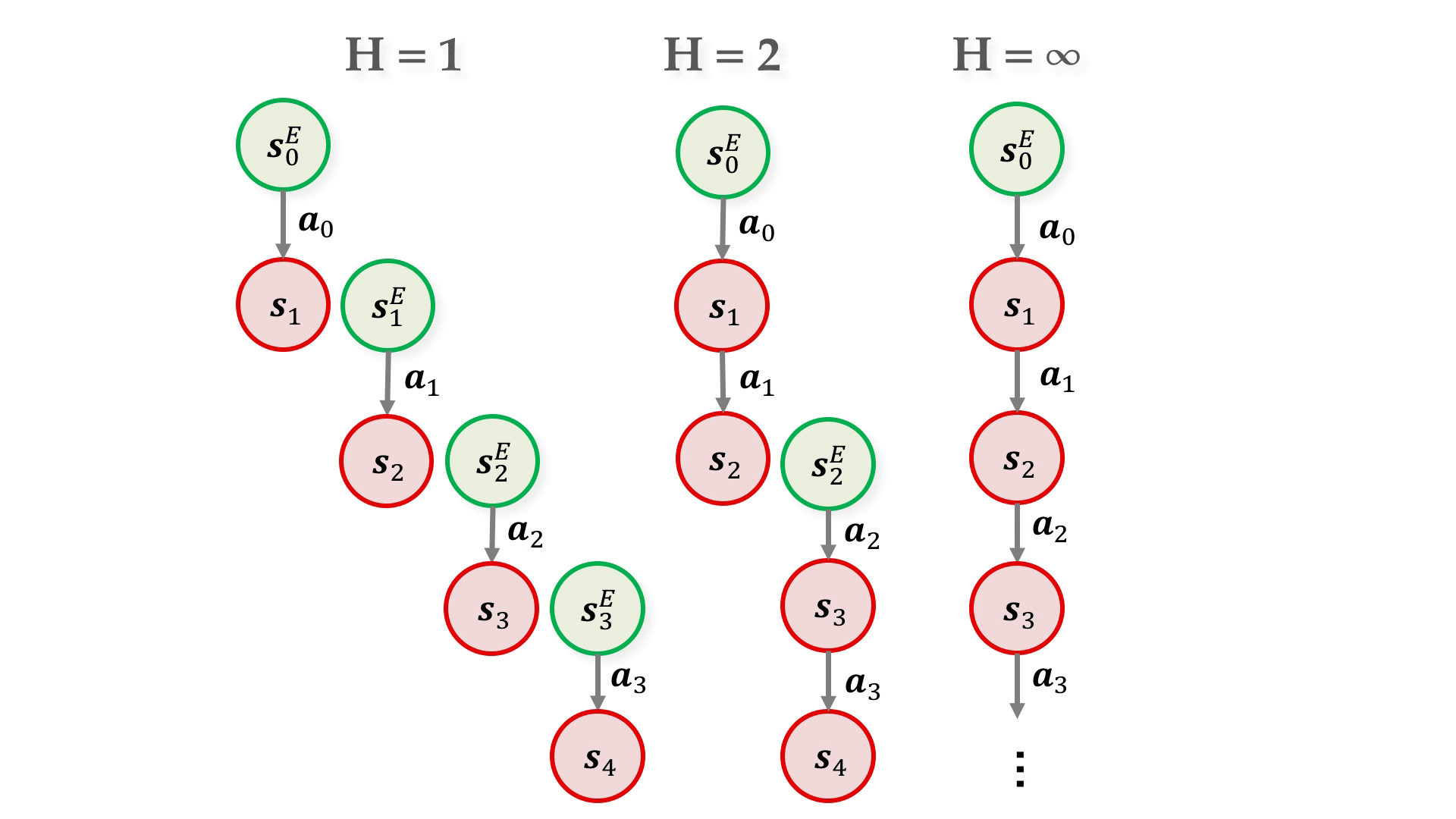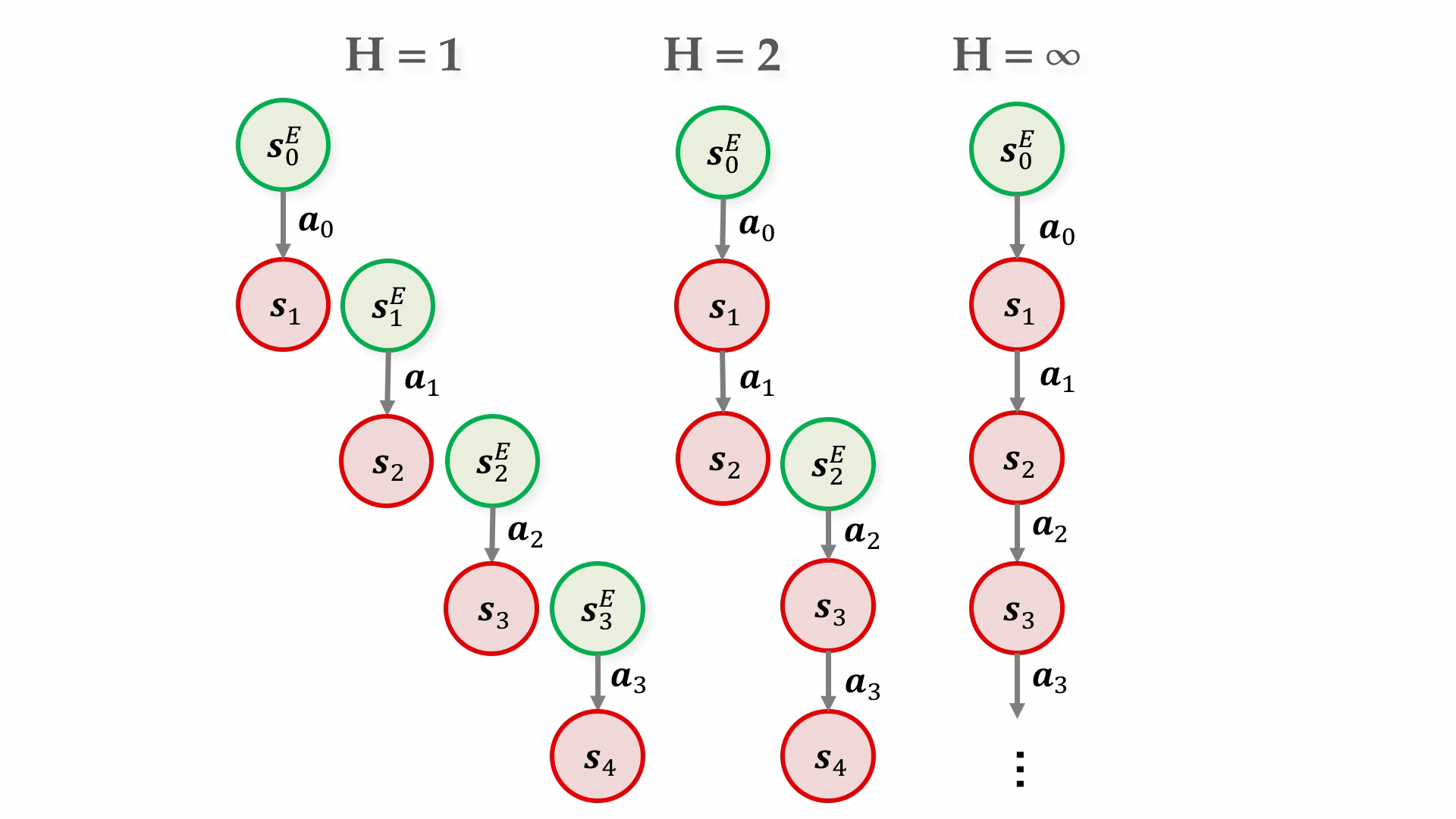
Acme: A Research Framework for Distributed Reinforcement Learning
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.

Analysing Deep Reinforcement Learning Agents Trained with Domain Randomisation
Deep reinforcement learning has the potential to train robots to perform complex tasks in the real world without requiring accurate models of the robot or its environment. A practical approach is to train agents in simulation, and then transfer them to the real world. One popular method for achieving transferability is to use domain randomisation, which involves randomly perturbing various aspects of a simulated environment in order to make trained agents robust to the reality gap. However, less work has gone into understanding such agents - which are deployed in the real world - beyond task performance. In this work we examine such agents, through qualitative and quantitative comparisons between agents trained with and without visual domain randomisation. We train agents for Fetch and Jaco robots on a visuomotor control task and evaluate how well they generalise using different testing conditions. Finally, we investigate the internals of the trained agents by using a suite of interpretability techniques. Our results show that the primary outcome of domain randomisation is more robust, entangled representations, accompanied with larger weights with greater spatial structure; moreover, the types of changes are heavily influenced by the task setup and presence of additional proprioceptive inputs. Additionally, we demonstrate that our domain randomised agents require higher sample complexity, can overfit and more heavily rely on recurrent processing. Furthermore, even with an improved saliency method introduced in this work, we show that qualitative studies may not always correspond with quantitative measures, necessitating the combination of inspection tools in order to provide sufficient insights into the behaviour of trained agents.
Modular Meta-Learning with Shrinkage
The modular nature of deep networks allows some components to learn general features, while others learn more task-specific features. When a deep model is then fine-tuned on a new task, each component adapts differently. For example, the input layers of an image classification convnet typically adapt very little, while the output layers may change significantly. However, standard meta-learning approaches ignore this variability and either adapt all modules equally or hand-pick a subset to adapt. This can result in overfitting and wasted computation during adaptation. In this work, we develop techniques based on Bayesian shrinkage to meta-learn how task-independent each module is and to regularize it accordingly. We show that various recent meta-learning algorithms, such as MAML and Reptile, are special cases of our formulation in the limit of no regularization. Empirically, our approach discovers a small subset of modules to adapt, and improves performance. Notably, our method finds that the final layer is not always the best layer to adapt, contradicting standard practices in the literature.
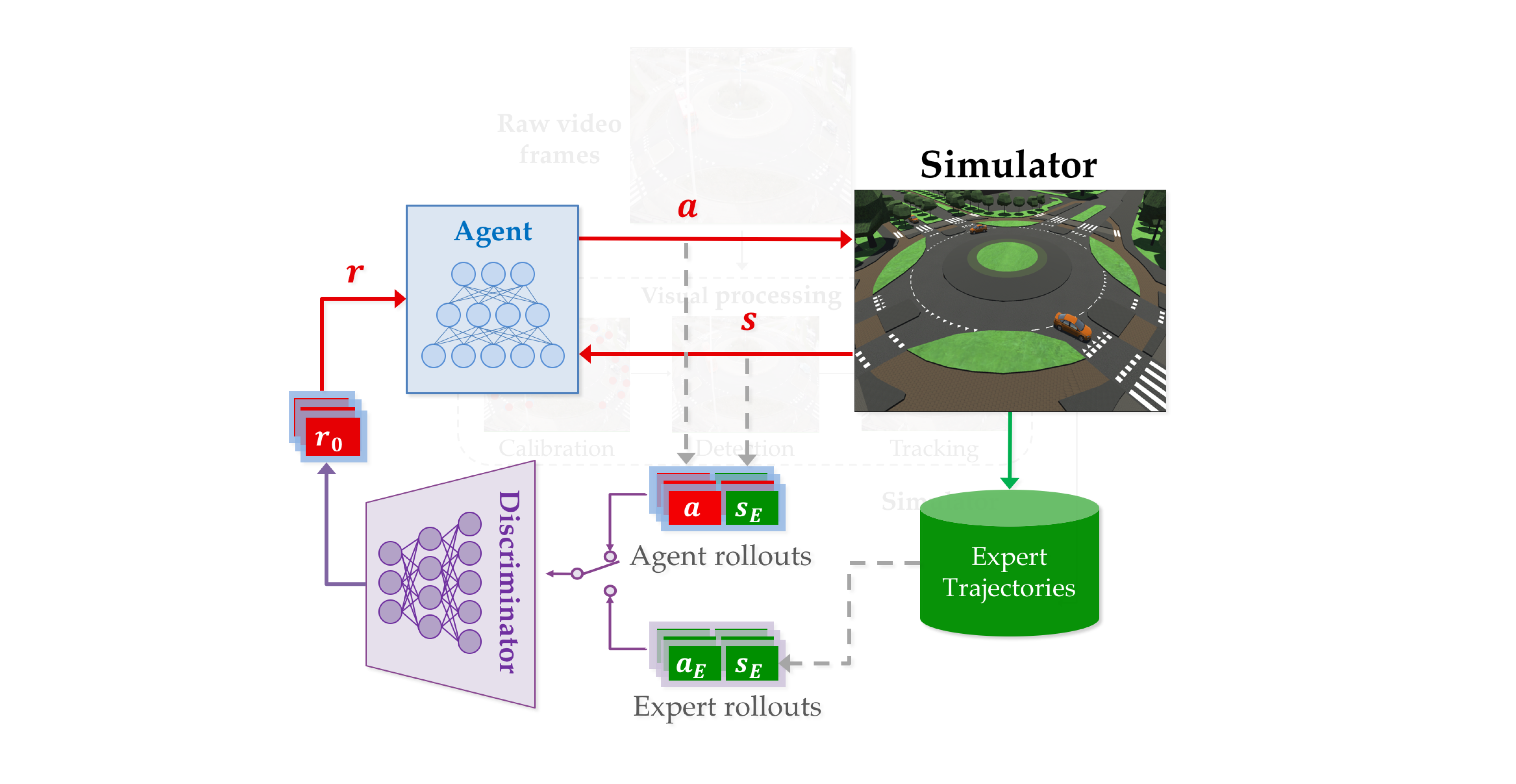
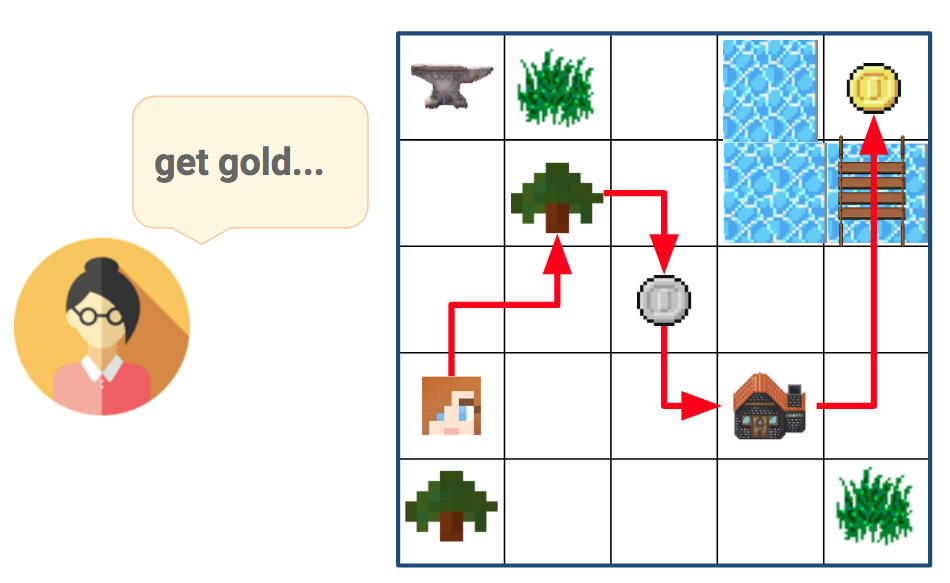
Learning from Demonstration in the Wild
Learning from demonstration (LfD) is useful in settings where hand-coding behaviour or a reward function is impractical. It has succeeded in a wide range of problems but typically relies on artificially generated demonstrations or specially deployed sensors and has not generally been able to leverage the copious demonstrations available in the wild: those that capture behaviour that was occurring anyway using sensors that were already deployed for another purpose, e.g., traffic camera footage capturing demonstrations of natural behaviour of vehicles, cyclists, and pedestrians. We propose video to behaviour (ViBe), a new approach to learning models of road user behaviour that requires as input only unlabelled raw video data of a traffic scene collected from a single, monocular, uncalibrated camera with ordinary resolution. Our approach calibrates the camera, detects relevant objects, tracks them through time, and uses the resulting trajectories to perform LfD, yielding models of naturalistic behaviour. We apply ViBe to raw videos of a traffic intersection and show that it can learn purely from videos, without additional expert knowledge.
ICRA 2019
Reverse-Engineering Human Visual and Haptic Perceptual Algorithms
Intelligent behaviour is fundamentally tied to the ability of the brain to make decisions in uncertain and dynamic environments. In neuroscience, the generative framework of Bayesian Decision Theory has emerged as a principled way to predict how the brain acts in the face of uncertainty. In the first part of my thesis, I study the question of how humans learn to perform a visual object categorisation task. I present a novel experimental paradigm to assess whether people use generative Bayesian principles as a general strategy. We found that humans indeed perform in a generative manner, but resort to approximate inference when faced with complex computations. In the second part, I consider how one would build a Bayesian ideal observer model of human haptic perception and object recognition, using MuJoCo as an environment. Our model can, using only noisy contact point information on the surface of the hand and noisy hand proprioception, simultaneously infer the shape of simple objects together with an estimation of the true hand pose in space. This is implemented using a recursive Bayesian estimation algorithm, inspired by simultaneous localisation and mapping (SLAM) methods in robotics, which can operate on computer-based physical simulations as well as experimental data from human subjects.
Thesis
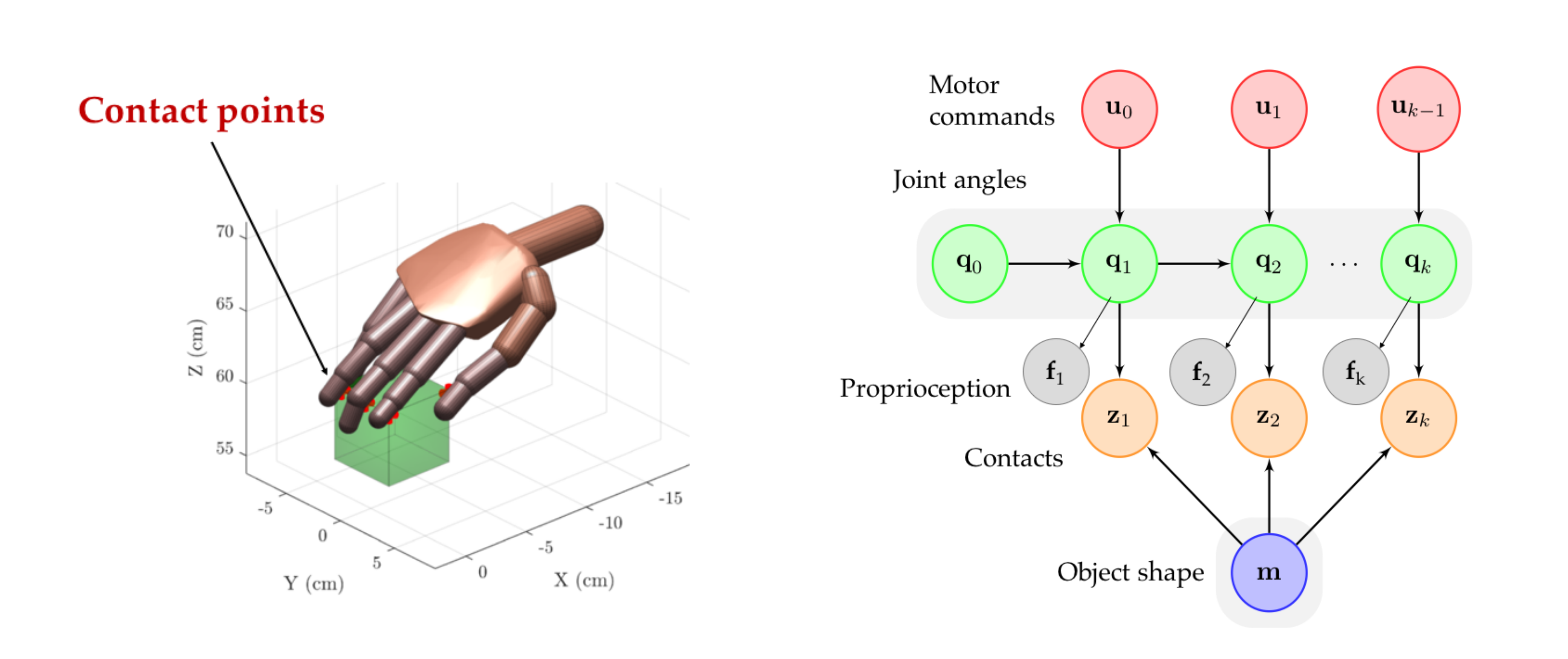
Haptic SLAM: An Ideal Observer Model for Bayesian Inference of Object Shape and Hand Pose from Contact Dynamics
Dynamic tactile exploration enables humans to seamlessly estimate the shape of objects and distinguish them from one another in the complete absence of visual information. Such a blind tactile exploration allows integrating information of the hand pose and contacts on the skin to form a coherent representation of the object shape. A principled way to understand the underlying neural computations of human haptic perception is through normative modelling. We propose a Bayesian perceptual model for recursive integration of noisy proprioceptive hand pose with noisy skin–object contacts. The model simultaneously forms an optimal estimate of the true hand pose and a representation of the explored shape in an object–centred coordinate system. A classification algorithm can, thus, be applied in order to distinguish among different objects solely based on the similarity of their representations. This enables the comparison, in real–time, of the shape of an object identified by human subjects with the shape of the same object predicted by our model using motion capture data. Therefore, our work provides a framework for a principled study of human haptic exploration of complex objects.
In Haptics: Perception, Devices, Control, and Applications. Lecture Notes in Computer Science (Finalist for best paper at EuroHaptics 2016).