Abstract
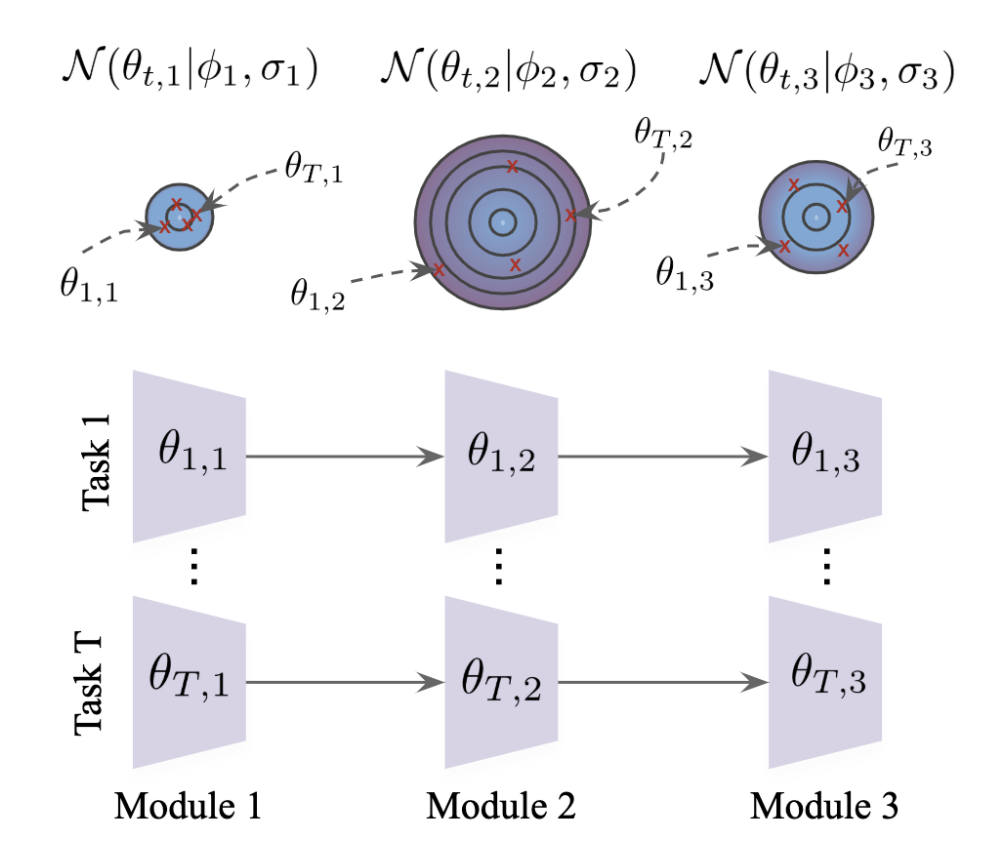
The modular nature of deep networks allows some components to learn general features, while others learn more task-specific features. When a deep model is then fine-tuned on a new task, each component adapts differently. For example, the input layers of an image classification convnet typically adapt very little, while the output layers may change significantly. However, standard meta-learning approaches ignore this variability and either adapt all modules equally or hand-pick a subset to adapt. This can result in overfitting and wasted computation during adaptation. In this work, we develop techniques based on Bayesian shrinkage to meta-learn how task-independent each module is and to regularize it accordingly. We show that various recent meta-learning algorithms, such as MAML and Reptile, are special cases of our formulation in the limit of no regularization. Empirically, our approach discovers a small subset of modules to adapt, and improves performance. Notably, our method finds that the final layer is not always the best layer to adapt, contradicting standard practices in the literature.